
虚拟地址到物理地址映射
前言
程序在编译链接完成后所有指令虚拟地址就已经确定了,CPU在执行到某条指令,得到它的虚拟地址,然后通过其芯片里的MMU硬件将虚拟地址转换为物理地址,然后先去CPU芯片里的高速缓存中获取数据,如果没有再去内存中获取(这里程序会自动预测CPU下次指令要执行的数据,会提前把数据从内存传递到高速缓存中)。
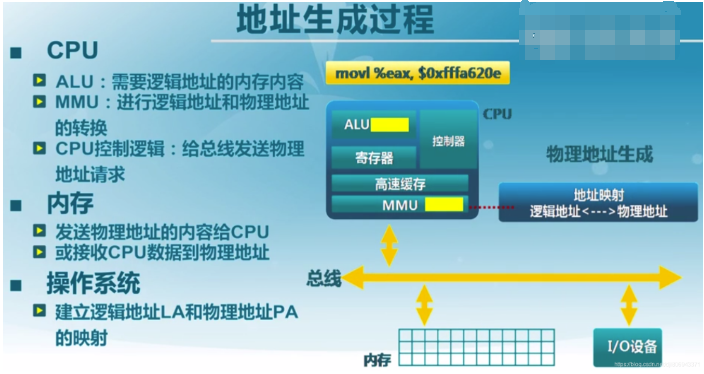
其中虚拟地址映射到物理地址的实现大体经历了4次优化历程,下面依次分析。
名词约定:
va: 虚拟地址
pa: 物理地址
一 “%”取模
pa = va % pa_max_len
最早就是用这种取模的方式来做映射的,它保证了虚拟地址映射不会越界。但是有个很明显的问题,就是地址冲突,同时只能运行一个程序,不能多开。
二 哈希
后来为了解决地址冲突问题,我们想到了用哈希map来实现,va–>hashmap–>pa,它能保证每个va都能映射唯一的pa,解决了地址冲突的问题。
但是通过hashmap计算出的pa地址分布是凌乱的,这样寻址就会很低效。
三 段地址
既然哈希算法转换的地址凌乱分布,导致寻址低效。那么有没有办法使得一段连续虚拟地址对应的物理地址也连续了?
后面人们想到了用一段段连续空间来表示,如下图,程序p2分布在两个段空间内,段内地址是连续的,那么我们记录这样的段空间就可以用(va0, pa0, D)一个三元组来表示。va0是段虚拟地址的起始地址,pa0是物理地址的起始地址,D是段空间范围。
那么我们要映射某个物理地址va,过程是这样,先循环判断条件 va0 <= va <= va0 + D,找出va属于哪个段,然后 pa = va - va0 + pa0;
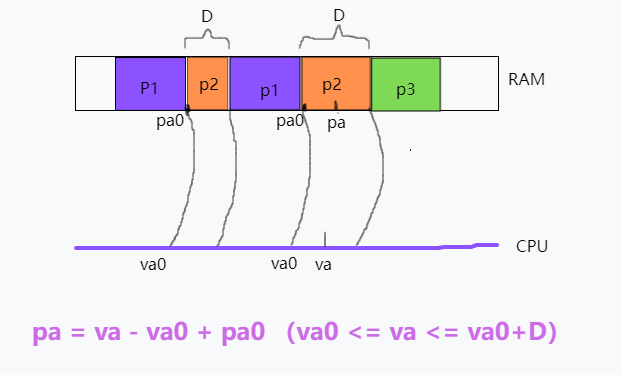
这种方式解决了映射地址分布凌乱的问题,但是我们发现段的范围D是不固定的,根据当前内存使用情况决定。随着各种程序运行推移,一个程序很难找到一段比较长的空闲空间,他会分布到多个段空间中,碎片化越来越严重。
而且还一个问题是每次映射都要先查找属于哪个段的条件判断,这也是麻烦之一。
四 多级分页
最终我们想到了让D保持不变,一般默认是4kb大小,这样的话我们描述映射表就只需要一个二元组了(va0, pa0),甚至我们还可以直接用表的key索引来当va0字段,这样就只需要一个字段pa0记录了。
同时把内存分成一个个固定大小的页来作为最小的储存单元,这样相对不定长的段碎片也会少很多。
不过了光只是一层分页还不够,还可以再进一步优化,即多级分页,一般分到4层,每层4等分。那为什么要这么干了?下面我们来分析下其中缘由:
对于我们64位cpu一般va寻址范围是2^48,首先我们按4kb(2^12)分页,总共页数= 2^48 / 2^12 = 2^36.
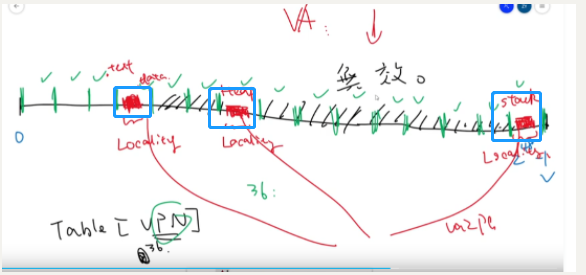
假设有个程序只分布在上图中的3个区域,那么这样就有个问题,这个程序有效数据其实只有图中的3个区域,但是我们却要申请2^36这么大一个数组来记录,大部分都是无效数据。
怎么优化了,那就是再往下分,每次4等分。
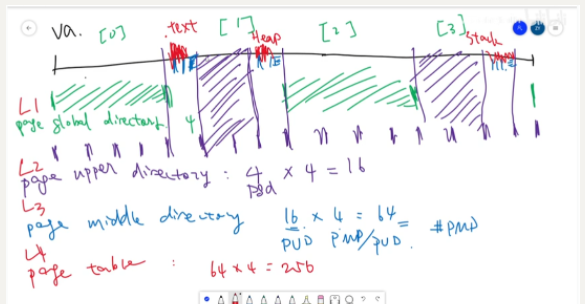
这样是不是这个程序的3个区域只在4(0~3)等分后的第1和第3个分区里。那么我们就只需要记录第1和第3个分区。依次类推再往下分,要记录的无效数据就会越来越少,即所要申请的记录数组越小。