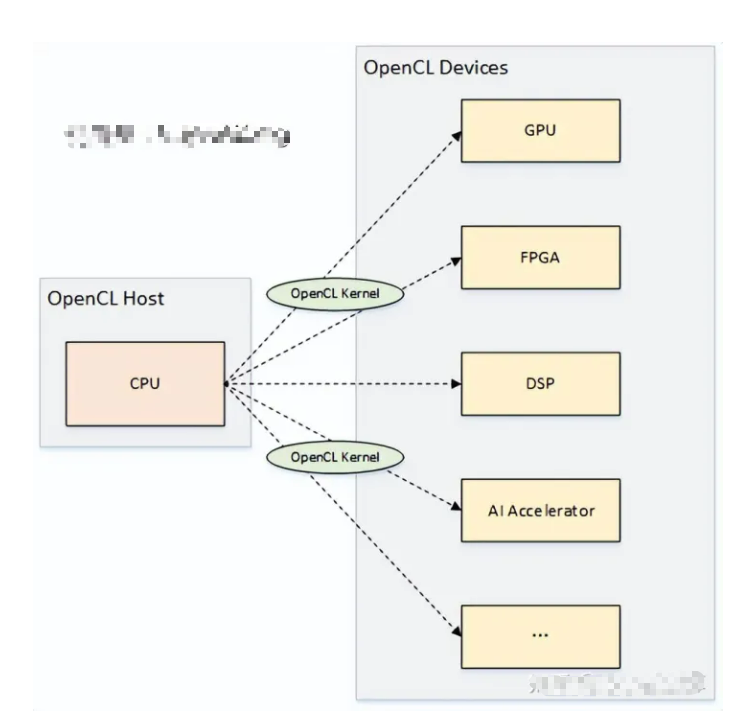
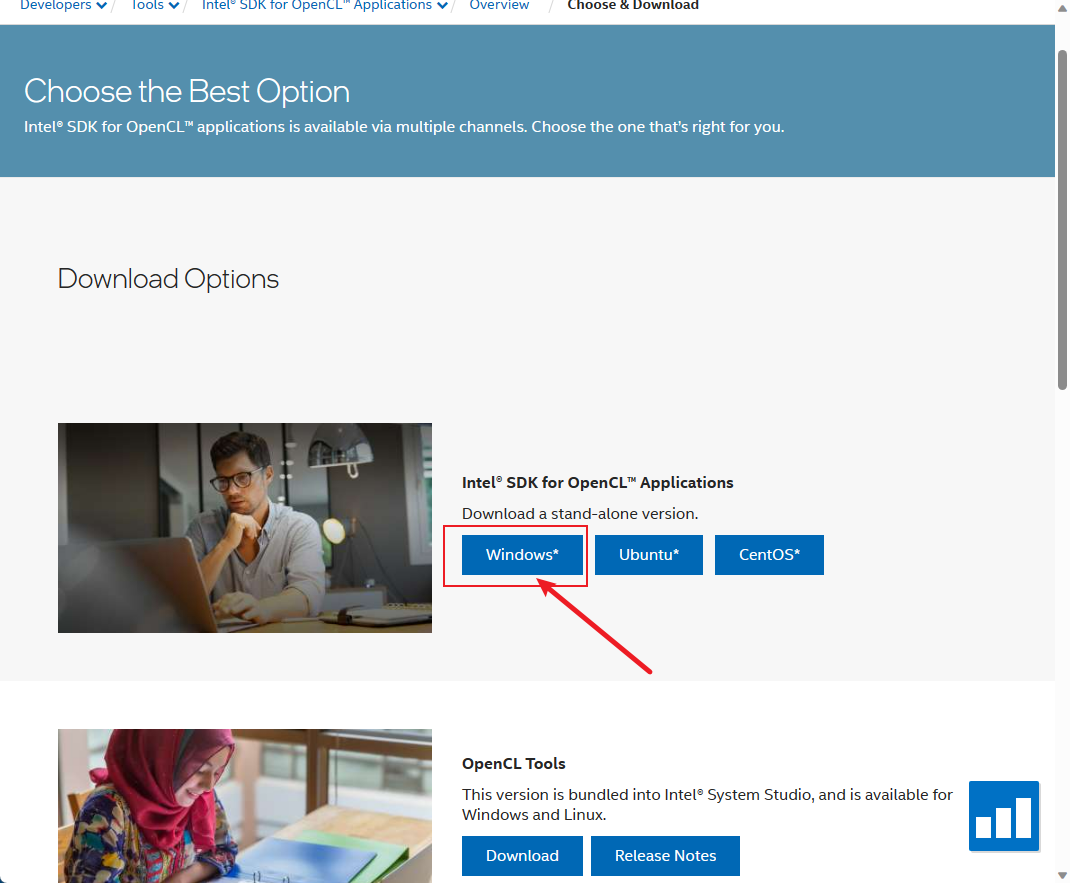
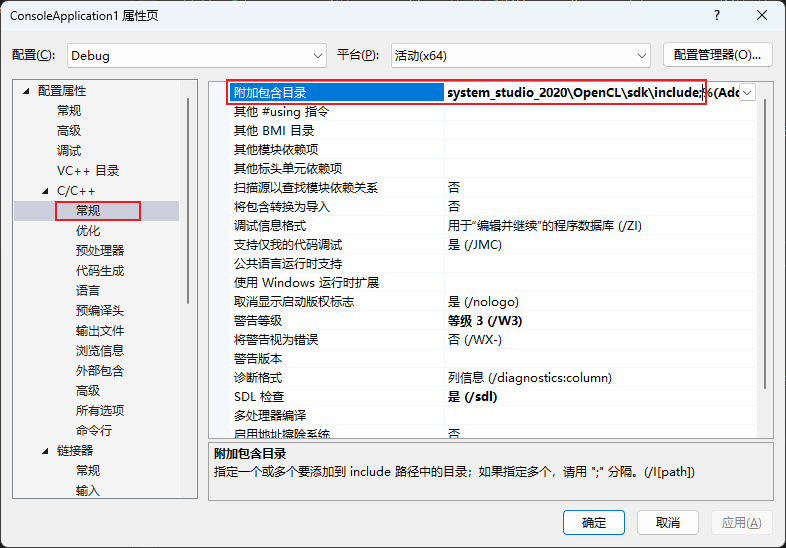
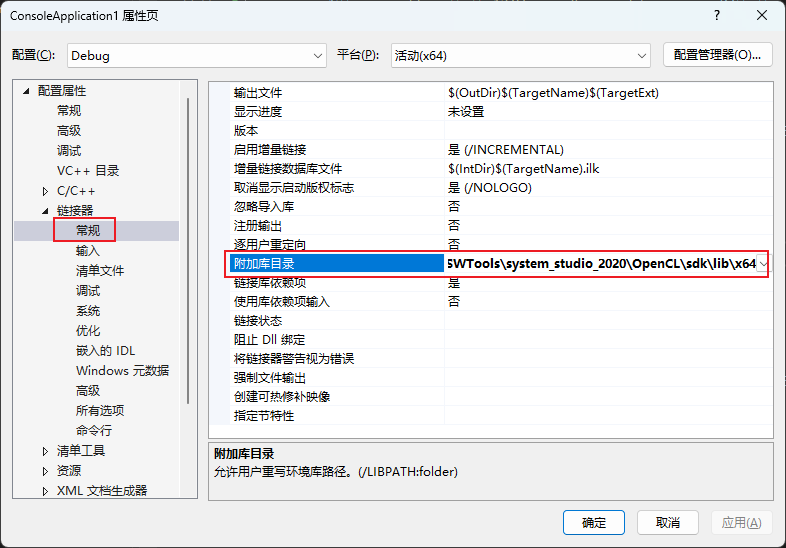
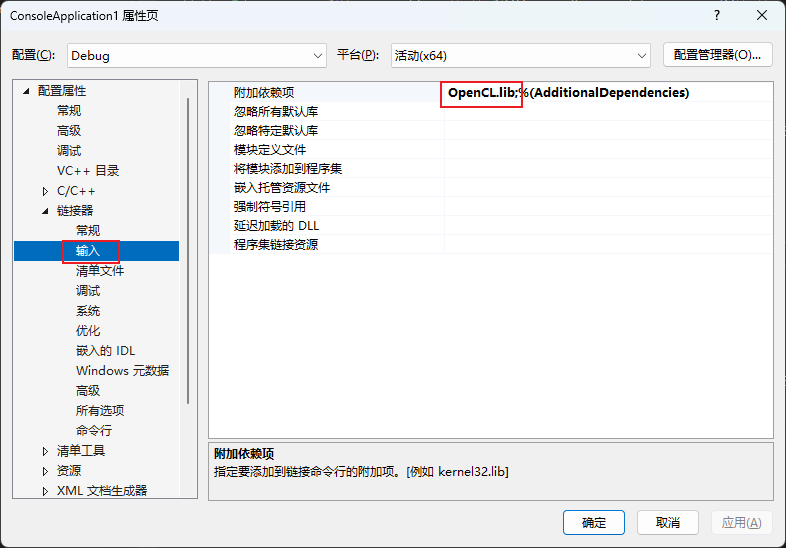
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
| #include <CL/cl.h>
#include <fstream>
#include <iostream>
#include <sstream>
const int ARRAY_SIZE = 1000;
cl_context CreateContext()
{
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0) {
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
}
cl_context_properties contextProperties[] = {
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformId,
0
};
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_GPU,
NULL, NULL, &errNum);
return context;
}
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id* device)
{
cl_int errNum;
cl_device_id* devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (deviceBufferSize <= 0) {
std::cerr << "No devices available.";
return NULL;
}
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
commandQueue = clCreateCommandQueueWithProperties(context, devices[0], 0, NULL);
*device = devices[0];
delete[] devices;
return commandQueue;
}
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
{
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open()) {
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
}
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char* srcStr = srcStdStr.c_str();
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
return program;
}
bool CreateMemObjects(cl_context context, cl_mem memObjects[3],
float* a, float* b)
{
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float) * ARRAY_SIZE, a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float) * ARRAY_SIZE, b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE,
sizeof(float) * ARRAY_SIZE, NULL, NULL);
return true;
}
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem memObjects[3])
{
for (int i = 0; i < 3; i++) {
if (memObjects[i] != 0)
clReleaseMemObject(memObjects[i]);
}
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (context != 0)
clReleaseContext(context);
}
int main(int argc, char** argv)
{
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = { 0, 0, 0 };
cl_int errNum;
context = CreateContext();
commandQueue = CreateCommandQueue(context, &device);
program = CreateProgram(context, device, "HelloWorld.cl");
kernel = clCreateKernel(program, "hello_kernel", NULL);
float result[ARRAY_SIZE];
float a[ARRAY_SIZE];
float b[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
a[i] = (float)i;
b[i] = (float)(ARRAY_SIZE - i);
}
if (!CreateMemObjects(context, memObjects, a, b)) {
Cleanup(context, commandQueue, program, kernel, memObjects);
return 1;
}
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
size_t globalWorkSize[1] = { ARRAY_SIZE };
size_t localWorkSize[1] = { 1 };
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE,
0, ARRAY_SIZE * sizeof(float), result,
0, NULL, NULL);
for (int i = 0; i < ARRAY_SIZE; i++) {
std::cout << result[i] << " ";
}
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
getchar();
Cleanup(context, commandQueue, program, kernel, memObjects);
return 0;
}
|